Sincronização de arquivos
Uma ferramenta para sincronização dos arquivos deve ser adotada, de maneira a replicar os dados de um servidor para os demais participantes.
Essa ferramenta deve:
Detectar mudanças instantaneamente
Minimizar overhead de rede
Oferecer mecanismos eficientes de transferência
Suportar delta-transfer (só enviar as partes modificadas)
O que levar em conta ao escolher uma tecnologia de sincronização
Taxa de transferência
IOPS (Operações de Entrada/Saída)
Escalabilidade
Resiliência
Tempo de Recuperação e Plano de recuperação em desastres
Estratégias de replicação
Overhead
Replicação Geográfica
Ferramentas disponíveis
Algumas ferramentas para sincronizar dados:
É possível configurar o Nextcloud para utilizar armazenamento em objeto como seu primeiro armazenamento, dispensando o uso de uma pasta localmente.
Também é possível configurar múltiplos buckets a serem utilizados.
Opções object storage:
Abaixo, uma tabela comparativa produzida por Grey Skipwith, 2023
Ceph |
GlusterFS |
HDFS |
|
|---|---|---|---|
Arquitetura |
Distribuída |
Descentralizada |
Centralizada |
Gerenciamento de Metadados |
Múltiplos MDSs |
Sem MDS |
Um MDS |
Método de Armazenamento Subjacente |
Baseado em Objeto |
Baseado em Arquivo |
Baseado em Bloco |
Modelo de Escalabilidade |
Horizontal |
Horizontal |
Horizontal |
Caso de Uso Principal |
Armazenamento Unificado |
Sistema de Arquivos |
Armazenamento de Big Data |
Interface de Armazenamento |
Arquivo, Bloco, Objeto |
Arquivo |
Arquivo |
Garage S3
“Garage é um armazenamento de dados geodistribuído leve que implementa o protocolo de armazenamento de objetos Amazon S3. Ele permite que aplicativos armazenem grandes blobs, como fotos, vídeos, imagens, documentos, etc., em uma configuração redundante de vários nós. O S3 é versátil o suficiente para também ser usado para publicar um site estático”
Características do GarageS3:
Habilitado para Internet: feito para vários sites (por exemplo, datacenters, escritórios, residências, etc.) interconectados por meio de conexões regulares de Internet.
Autocontido e leve: funciona em qualquer lugar e se integra bem em ambientes existentes para atingir infraestruturas hiperconvergentes.
Altamente resiliente: altamente resiliente a falhas de rede, latência de rede, falhas de disco, falhas de administrador de sistema.
Simples: simples de entender, simples de operar, simples de depurar.
Desempenhos extremos: altos desempenhos restringem muito o design e a infraestrutura; buscamos desempenhos apenas por meio do minimalismo.
Extensividade de recursos: não planejamos adicionar recursos adicionais em comparação aos fornecidos pela API S3.
Otimizações de armazenamento: codificação de apagamento ou qualquer outra técnica de codificação aumentam a dificuldade de colocar dados e sincronizar; nos limitamos à duplicação.
Compatibilidade POSIX/Sistema de arquivos: não pretendemos ser compatíveis com POSIX ou emular qualquer tipo de sistema de arquivos. De fato, em um ambiente distribuído, tais sincronizações são traduzidas em mensagens de rede que impõem restrições severas à implantação.
Ponto negativo: não faz a checagem de integridade dos dados.
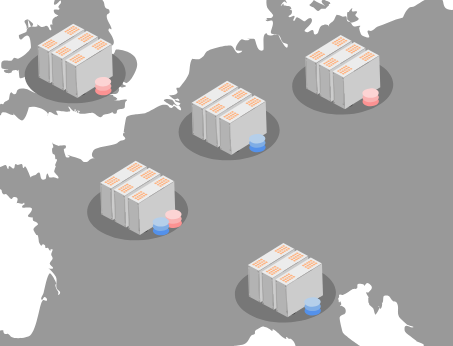
Na imagem abaixo existem 5 zonas com múltiplos servidores em cada zona. Os círculos vermelhos e azuis representam dados, os quais estão espalhados pelas zonas. Repare que cada dado é replicado 3 vezes.
Configuração
Disponível nesse repositório.
GlusterFS
Os servidores usados para criar o pool de armazenamento devem ser resolvíveis pelo nome do host.
O daemon glusterd deve estar em execução em todos os servidores de armazenamento que você deseja adicionar ao pool de armazenamento.
O firewall nos servidores deve ser configurado para permitir acesso às portas
tcp111, 24007, 24008.Cada volume montado utiliza uma porta, por exemplo, teríamos de liberar a porta
24009caso tenhamos 1 volume montado.Caso tenhamos mais, precisamos liberar conexão para portas acima da
24009, no caso,24010e assim por diante.Essa porta base é configurável nas configurações do gluster.
No seu serviço de DNS, adicione as entradas do tipo A para os servidores.
Exemplo de cenário:
server1.librecode.coop - 189.x.x.x
server2.librecode.coop - 177.x.x.x
server3.librecode.coop - 38.x.x.x
No arquivo /etc/hosts será necessário adicionar os servidores, também:
Nota
Configure o endereço IP que está fixado na interface de rede do seu servidor.
- Por exemplo, o arquivo /etc/hosts no servidor 1::
# Servidor 1 192.168.1.253 gluster01.dominio.coop # Servidor 2 200.57.1.43 gluster02.dominio.coop
Idealmente o diretório contendo os arquivos que serão sincronizados devem ficar em outro disco, separado do sistema operacional:
apt update
apt install glusterfs-server -y
systemctl start glusterd
systemctl enable glusterd
No servidor 1:
gluster peer probe servidor2
gluster peer probe servidor3
No servidor 2, com o comando gluster peer status:
# gluster peer status
Number of Peers: 2
Hostname: server1.librecode.coop
Uuid: fa9c3f27-0b60-4718-93bd-b54b79e84e66
State: Peer in Cluster (Connected)
Other names:
server1.librecode.coop
Hostname: server3.librecode.coop
Uuid: 3418bdcc-8f9d-4082-993b-121656fcea14
State: Peer in Cluster (Connected)
No servidor 2:
gluster peer probe servidor1
gluster peer probe servidor3
Em todos servidores, crie um diretório a ser compartilhado:
mkdir -p /data/brick1/gv0
O próximo passo é criar o volume, definir o número de réplicas e qual diretório será parte do volume. Crie o volume e defina o número de réplicas:
gluster volume create gv0 replica 3 server1.librecode.coop:/data/brick1/gv0 server2.librecode.coop:/data/brick1/gv0 server3.librecode.coop:/data/brick1/gv0 force
Nota
Se for réplica entre 2 servidores, mude o valor para ``replica 2
Inicialize o volume:
gluster volume start gv0
- O próximo passo é montar o volume para ser utilizado::
# Sintaxe mount.glusterfs “servidor onde será montado (o qual você está)”:”diretório criado anteriormente” “caminho do diretório dos arquivos que serão acessados” mount.glusterfs server1.librecode.coop:/data/brick1/gv0 /mnt/dados-sincronizados
Montando volumes automaticamente
Adicione ao /etc/fstab:
HOSTNAME:/NOME-DO-VOLUME PONTO-DE-MONTAGEM glusterfs defaults,_netdev 0 0
Exemplo:
server1.librecode.coop:/data/brick1/gv0 /data/brick1/gv0 glusterfs defaults,_netdev 0 0
Segurança
Para restringir acesso aos diretórios, podemos utilizar a diretiva auth.allow.
Veja o exemplo abaixo:
gluster volume set test-vol auth.allow "/(192.168.10.*|192.168.11.*),/outro-diretorio-1(192.168.1.*),/outro-diretorio-2(192.168.8.*)"
Especifica que:
A pasta raíz, definido pela ‘/’, poderá ser montada por máquinas nas subredes 192.168.10.* e 192.168.11.*.
Desafio: Você consegue dizer quem consegue montar as pastas ‘outro-diretorio-1’ e ‘outro-diretorio-2?
Outro exemplo, agora especificando os endereços que podem acessar todo volume gv0:
gluster volume set gv0 auth.allow "192.168.1.10,192.168.15.120,192.168.20.20"
Agora vamos precisar montar esse volume no servidor, seguindo essa sintaxe mount.glusterfs <hostname>:<nome_do_volume> <ponto_de_montagem>. O hostname pode ser de qualquer servidor que esteja presente no cluster.
No servidor 1:
mkdir /data/brick1/gv0
mount.glusterfs server1.librecode.coop:/gv0 /data/brick1/gv0
Onde se lê gv0 é o volume no gluster. Os volumes gluster podem ser verificados com o comando gluster volume list. Onde se lê /data/brick1/gv0 é o diretório criado em cada servidor que foi feito no passo anterior (ou em algum momento).
Vamos testar, criando arquivos no volume:
for i in `seq -w 1 100`; do cp -rp /var/log/dpkg.log /data/brick1/gv0/copy-test-$i; done
Verificando se foram criados (essa pasta deve ser igual em todos servidores a partir de agora):
ls -lha /data/brick1/gv0
Monitoramento
Listando os 30 arquivos que são mais lidos:
gluster volume top nome-do-volume read list-cnt 30
Listando os 30 diretórios que são mais abertos:
gluster volume top nome-do-volume opendir list-cnt 30
Listando os 30 diretórios que são mais lidos:
gluster volume top nome-do-volume readdir list-cnt 30
Verificando status do volume:
gluster volume status nome-do-volume detail
Listando os clientes que estão acessando o volume:
gluster volume status nome-do-volume clients
Considerações de performance
Ao sincronizar todo o diretório do Nextcloud (dados + código) não houve um desempenho satisfatório do GlusterFS. Aconselha-se utilizar um ponto de montagem separado do sistema operacional, e, mudar a pasta de dados dos usuários para o diretório o ponto de montagem a ser sincronizado.
Exemplo de alteração da pasta de dados (dados dos usuários):
# Coloque a instância em modo de manutenção
occ maintenance:mode --on
# Altere o diretório dos dados
occ config:system:set datadirectory --value='/novo/caminho/dos/dados'
# Sincronize os arquivos mantendo as permissões
rsync -az /caminho/antigo /novo/caminho/dos/dados
# Retire do modo de manutenção
occ maintenance:mode --off
Removendo volumes e reiniciando o cluster
Antes de desfazer o pareamento com outros servidores (com o comando gluster probe), é necessário remover os bricks do volume.
Reduza as réplicas para 1 de todos os bricks do volume. Por exemplo:
gluster volume remove-brick NOME-DO-VOLUME replica 1 serverY.librecode.coop:/data-brick1/gv0 force
E então saia do cluster:
gluster peer detach serverY.seudominio force
- Antes de deletar o volume, é necessário pará-lo::
gluster volume stop NOME-DO-VOLUME gluster volume delete NOME-DO-VOLUME
Volume replicado versus Geo-replicação
É possível configurar a geo-replicação. Na tabela abaixo podemos ver a diferença:
Replicação de Volumes |
Geo-replicação |
|---|---|
Espelha dados em clusters |
Espelha dados em clusters distribuídos geograficamente |
Fornece alta disponibilidade |
Garante backup de dados para recuperação de desastres |
Replicação síncrona (cada operação de arquivo é enviada entre todos os blocos). |
Replicação assíncrona (verifica as alterações nos arquivos periodicamente e as sincroniza ao detectar diferenças). |
Comandos úteis
Verificar detalhes de um volume:
gluster volume status NOME-DO-VOLUME detailClientes conectados a um volume:
gluster volume status NOME-DO-VOLUME clientsRemove “brick” do volume:
gluster volume remove-brick gluster-volume replica 2 server3.dominio.coop:/nome-do-brick force`
Problemas
transport endpoint not connected
Verifique se o firewall não está bloqueando a comunicação entre os servidores.
permissions on mountbroker-root directory are too liberal
O dono do diretório raiz (utilizado pelo gluster para ser montado posteriormente) deve ter as permissões de dono e grupo root e de acesso 0711.
Resolva com chmod 0711 -R /data/brick1/gv0
0-glusterfsd-mgmt: Exhausted all volfile servers
Verifique se o arquivo /etc/hosts está correto.
Exemplo de /etc/hosts:
.. code:
IP-DO-SERVIDOR server1.dominio.com.br
Porta TCP não disponível
Com o comando gluster volume status VOLUME detail é possível obter mais informações.
Se no campo TCP Port estiver com o valor N/A, significa que este servidor não está conseguindo se comunicar com os outros servidores.
Error: Host gfs1.dominio.com.br is not in ‘Peer in Cluster’ state
Possívelmente algo falhou na verificação inicial do cluster. Verifique se o seu arquivo /etc/hosts está correto.
Ansible role
No diretório roles é possível encontrar um role para utilizar no Ansible.
Inclua o
rolea sua playbook:--- - hosts: glusterfs_servers become: yes roles: - glusterfs
Adicione ao seu
inventory.inio endereço dos servidores:[glusterfs_servers] server1.exemplo.coop server2.exemplo.coop server3.exemplo.coop
Execute a playbook:
ansible-playbook -i inventory playbook.yml